All your data.
One query away.
HubSpot. Stripe. Google Analytics. Your database.
Stop copy-pasting between tabs.







Built-in connectors
+ any REST / GraphQL API via JSON spec

HubSpot and Stripe in the same editor. One query, joined live.
Or ask in plain English.
“Which campaigns drove the most revenue last quarter?” rawquery connects to Claude, Cursor, and ChatGPT. You ask, it answers.
$ curl -sSL rawquery.dev/install.sh | sh
$ rq signup && rq claude-init
$ claude
> which campaigns drove the most revenue last quarter?CLI installs the /rq skill. Claude sees your schemas, joins Stripe and HubSpot, runs the SQL. Also works in Cursor and Windsurf.
You run on 12 tools. Your reports run on Google Sheets.
Every week: export from HubSpot, export from Stripe, paste into a spreadsheet, fix the formulas, email the PDF. There's a better way.
-- Which deals from HubSpot actually converted to paying customers?
SELECT h.deal_name, h.close_date, s.total_revenue
FROM hubspot.deals h
JOIN my_stripe.customers s
ON h.contact_email = s.email
WHERE h.stage = 'closedwon'
ORDER BY s.total_revenue DESCHubSpot + Stripe in one query. No exports, no spreadsheets.
From query to chart in 30 seconds.
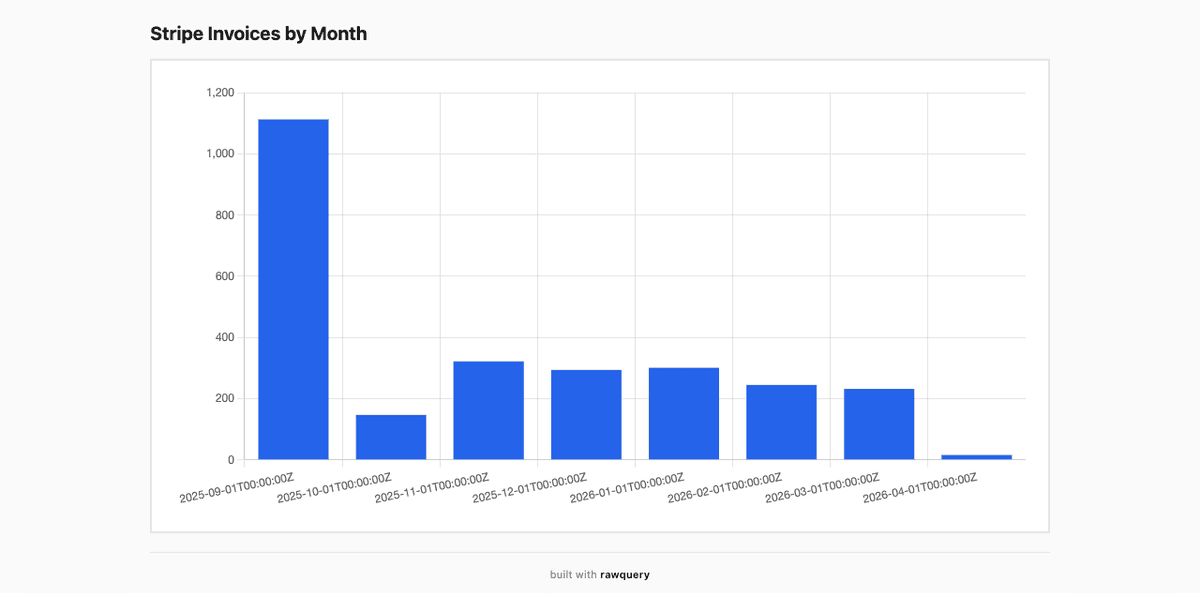
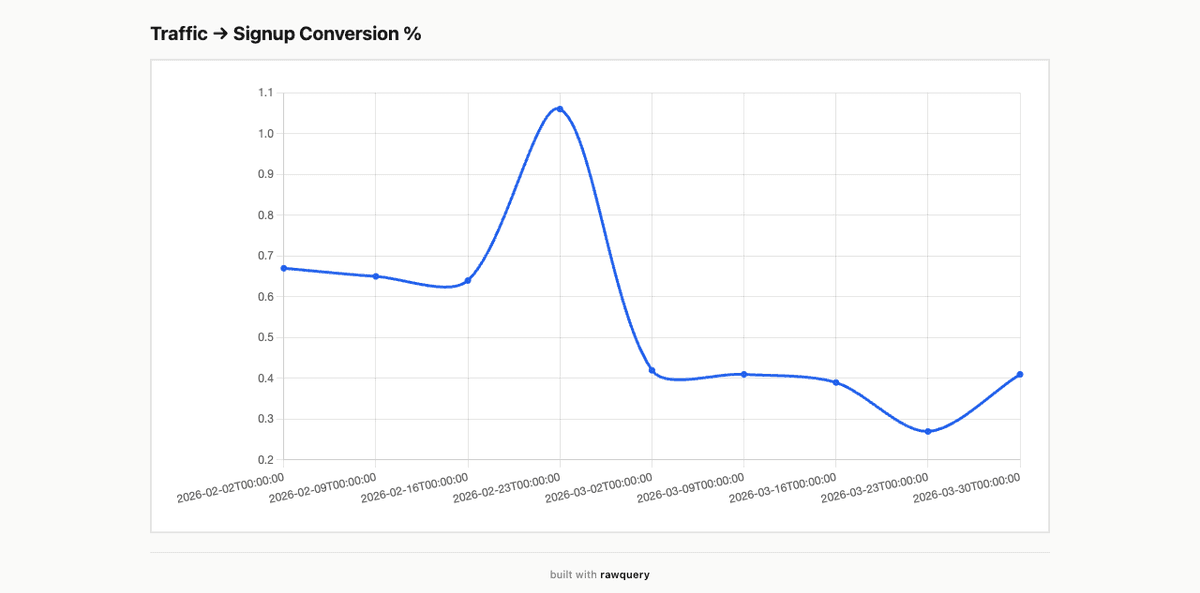
Real charts from real data. Published as shareable links.
Built for the people who need the numbers.
Growth / Marketing
Attribution across tools. Campaign ROI in one query. Share reports as live links.
RevOps / Sales Ops
Pipeline vs. revenue. HubSpot + Stripe joined. No more spreadsheet gymnastics.
Founders / Execs
KPI pages you can send to investors. Always live, always current.
Share a link, not a spreadsheet.
Publish charts and pages with one click. Password-protect if needed. Your team sees live data, not last Tuesday's export.

One URL. Always live. No login required.
Your data is already there. Go get it.
Connect your first source in under 2 minutes.